Overview
The HateSpeech Detection project is a machine learning-based system designed to classify text as either hate speech or non-hate speech using Natural Language Processing (NLP) techniques. By leveraging a balanced dataset from Kaggle, the project employs Logistic Regression combined with TF-IDF vectorization to analyze and categorize text. This system aims to assist in moderating online content, fostering safer digital environments by identifying harmful language. The project is implemented in Python and includes robust preprocessing, model training, and evaluation steps, making it a valuable tool for content moderation.


Data Sources
- Sourced from Kaggle, specifically the "Hate Speech Detection Curated Dataset" file named
HateSpeechDatasetBalanced.csv. - The dataset is balanced, containing an approximately equal number of hate speech and non-hate speech samples, critical for training a fair and unbiased model.
- Contains text and labels (0 for non-hate speech, 1 for hate speech), making it a good base for classification.
- Dataset Link: Hate Speech Detection Curated Dataset
Technologies Used
- Programming Language: Python
- Libraries and Tools:
- Pandas: For data manipulation and analysis, enabling efficient handling of the dataset.
- NumPy: For numerical operations, supporting matrix computations.
- re: For regular expression operations to clean text data by removing URLs and special characters.
- NLTK: For natural language processing tasks, specifically for removing English stopwords.
- Scikit-learn: For machine learning tasks, including:
- Text vectorization with
TfidfVectorizer - Model training with
LogisticRegression - Model evaluation using
accuracy_score,classification_report, andconfusion_matrix
- Text vectorization with
- Joblib: For saving and loading the trained model and vectorizer for future use.
- Matplotlib and Seaborn: For creating visualizations, such as confusion matrix heatmaps.
- WordCloud: For generating word clouds to visualize frequent words in hate and non-hate speech.
Key Features
- Preprocesses text (lowercase conversion, stopwords removal, URL and special character removal).
- Converts text to numerical features with TF-IDF vectorization (up to 5000 features).
- Trains a Logistic Regression model for binary classification of hate speech.
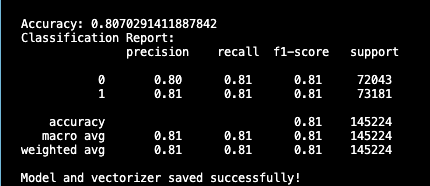
- Evaluates performance with accuracy (80.7%), precision, recall, and F1-score (~81%).
- Visualizes results with a confusion matrix heatmap and word clouds for hate and non-hate speech.
Model Training Process
- Preprocessing: Cleans text using regex (removes URLs, special characters), converts to lowercase, removes stopwords (
preprocess_text). - Feature Engineering: Applies TF-IDF vectorization with 5000 max features (
TfidfVectorizer). - Training: Splits data into 80% training and 20% testing sets, fits Logistic Regression model (
LogisticRegression). - Evaluation: Computes accuracy, generates classification report, plots confusion matrix and word clouds.
Model Performance
The model was trained on 80% of the dataset and evaluated on the remaining 20%, yielding the following performance metrics:
- Accuracy: 80.7% (correctly classified samples).
- Classification Report:
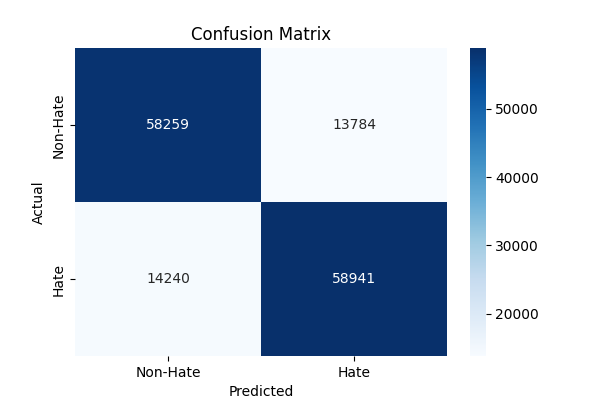
Class Precision Recall F1-Score Support 0 (Non-Hate) 0.80 0.81 0.81 72,043 1 (Hate) 0.81 0.81 0.81 73,181 Macro Avg 0.81 0.81 0.81 145,224 Weighted Avg 0.81 0.81 0.81 145,224 - Confusion Matrix:
Predicted: Non-Hate Predicted: Hate Actual: Non-Hate 58,259 (TN) 13,784 (FP) Actual: Hate 14,240 (FN) 58,941 (TP) - True Negatives (TN): 58,259 instances where non-hate speech was correctly identified.
- False Positives (FP): 13,784 instances where non-hate speech was incorrectly classified as hate speech.
- False Negatives (FN): 14,240 instances where hate speech was incorrectly classified as non-hate speech.
- True Positives (TP): 58,941 instances where hate speech was correctly identified.
- Insights: Balanced performance with precision, recall, and F1-scores around 0.81 for both classes, showing the model is equally effective at identifying hate and non-hate speech; however, false positives (~13,800) and false negatives (~14,200), totaling about 19% of the test set, suggest the need to reduce misclassifications for better real-world reliability.
- Visualizations: Confusion matrix heatmap visualizes correct and incorrect classifications; word clouds for hate and non-hate speech highlight frequent terms, offering qualitative insights into the text data.
Challenges Overcome
- Processed a large text dataset (145,224 samples) efficiently with TF-IDF vectorization.
- Achieved balanced performance using Logistic Regression on a binary classification task.
- Visualized complex text data with confusion matrix heatmaps and word clouds for better understanding.
Benefits
- Moderation: Identifies hate speech to support safer online spaces.
- Insightful: Reveals linguistic patterns in hate vs. non-hate content through word clouds.
- Reusable: Saved model and vectorizer (
hate_speech_model.pkl,tfidf_vectorizer.pkl) for future use.
Future Improvements
- Use deep learning models like BERT to improve accuracy by capturing contextual relationships in text.
- Deploy as a FastAPI web app to enable real-time hate speech detection for online platforms like social media.
- Add a user feedback loop in the web app to collect misclassification reports, enabling continuous model retraining and improvement.
- Add support for multiple languages by integrating translation APIs to preprocess non-English text into English for the current model.
- Ensure the model avoids biases against specific groups and minimizes misclassification of legitimate speech as hate speech.
Try It
Clone the repo, install dependencies, download the dataset, and run hate_speech_detection.py! See GitHub for setup.
Visit GitHub Repo